Abstract
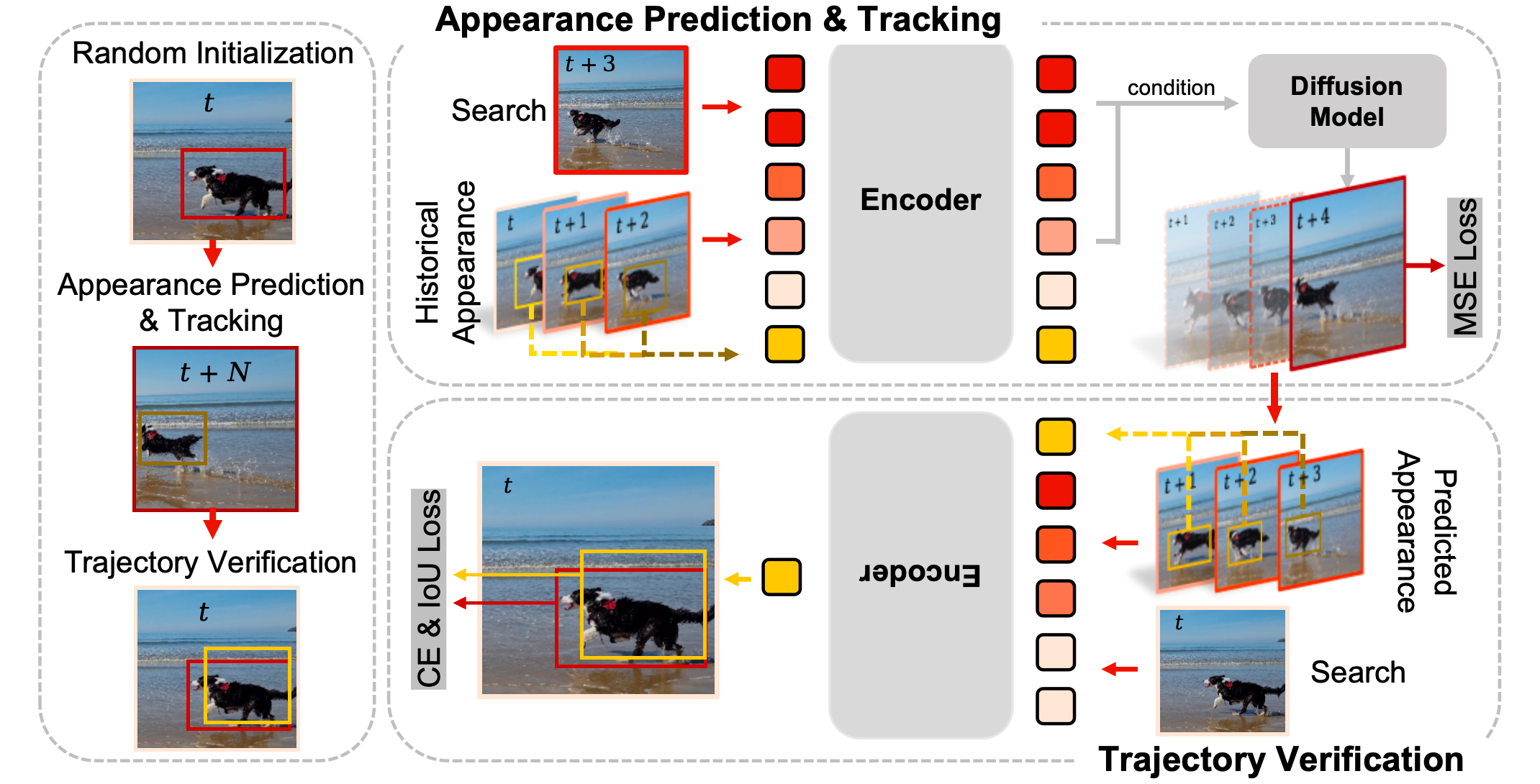
Recent advancements in visual object tracking have shifted towards a sequential generation paradigm, where object deformation and motion exhibit strong temporal dependencies. Despite the importance of these dependencies, widely adopted image-level pretrained backbones barely capture the dynamics in the consecutive video, which is the essence of tracking. Thus, we propose AutoRegressive Sequential Pretraining (ARP), an unsupervised spatio-temporal learner, via generating the evolution of object appearance and motion in video sequences. Our method leverages a diffusion model to autoregressively generate the future frame appearance, conditioned on historical embeddings extracted by a general encoder. Furthermore, to ensure trajectory coherence, the same encoder is employed to learn trajectory consistency by generating coordinate sequences in a reverse autoregressive fashion, a process we term back-tracking. Further, we integrate the pretrained ARP into ARTrackV2, creating ARPTrack, which is further fine-tuned for tracking tasks. ARPTrack achieves state-of-the-art performance across multiple benchmarks, becoming the first tracker to surpass 80% AO on GOT-10k, while maintaining high efficiency. These results demonstrate the effectiveness of our approach in capturing temporal dependencies for continuous video tracking.
Architecture